
参考自董伟明的Python Web开发实战
了解Celery前,可以先了解下任务与消息队列
Celery是一个专注于实时处理和任务调度的分布式任务队列
使用Celery常见场景:
- Web应用:当用户触发的一个操作需要较长时间才能执行完成时,可以把它作为任务交给Celery去异步执行,执行完再返回给用户。所谓异步就是要执行耗时的IO操作时,它只发出指令,不需要等待结果,然后去执行其他代码了;一段时间后,返回结果后再去处理。
- 定时任务:
- 其他可以异步执行的任务
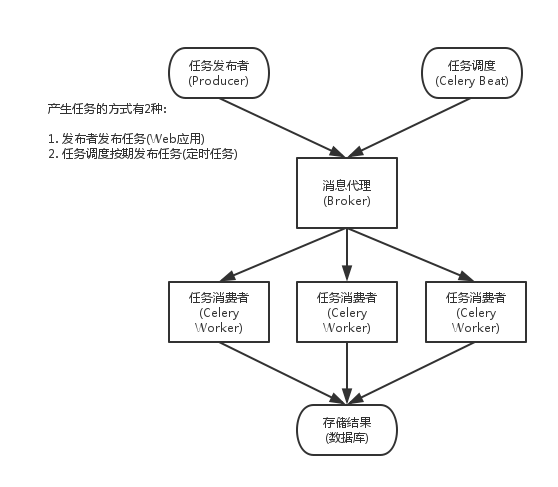
Celery的架构
- Celery Beat:任务调度器,Beat进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给消息队列
- Celery Worker:执行任务的消费者,通常会在多台服务器运行多个消费者来提高执行效率
- Broker:消息代理,或消息中间件,接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费方(通常是消息队列或者数据库)
- Producer:调用了Celery提供的API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者
- Result Backend:任务处理完后保存状态信息和结果,以供查询。Celery默认支持Redis、RabbitMQ、MongoDB、Django ORM
架构图:
选择消息代理
Celery目前支持RabbitMQ、Redis、MongoDB、Beanstalk等作为消息代理,但适用于生产环境的只有RabbitMQ和Redis
Celery序列化
- pickle
- json
- yaml
- magpack
安装配置Celery
- 选择Redis作为消息代理
- 选择Msgpack做序列化
- 选择Redis做结果存储
小试牛刀
首先用pipenv创建虚拟环境,附上昨天写的Pipenv简单小结
|
|
celery.py
|
|
存放任务函数的文件,tasks.py
tasks.py只有一个任务函数add,添加app.task来生效
|
|
配置文件celeryconfig.py
|
|
任务生产者tasks将任务交给消息中间件redis,存入队列,在按序发放给worker
cd celery_env 项目名字,随便写
celery -A proj worker -l info
-A参数会自动寻找proj.celery这个模块
|
|
开启另一个终端,用Ipython调用add函数
|
|
worker的终端上显示执行了任务
|
|
任务的结果都需要根据上面提到的task_id获得
|
|
指定队列
Celery会使用默认名为celery的队列用来存放任务,我们可以使用优先级不同的队列来确保高优先级的任务不需要等待就得到响应
我们在proj同目录下创建projq目录,将proj中的代码复制进projq,再给celeryconfig.py添加如下配置:
|
|
现在用指定队列的方式来启动worker ,worker只会执行web_tasks的任务
- -A自动寻找projq.celery
- -Q指定web_tasks队列
celery -A projq worker -Q web_tasks -l info
使用任务调度
之前的列子都是由发布者触发的,这里使用Celery的Beat进程自动生成任务,还记得前面的Celery架构图么,它和生产这一样都是处于任务发布者的位置
基于proj目录下的源码,创建一个projb目录,对projb/celeryconfig.py添加以下配置:
|
|
timedelta表示两个时间的差值,tasks.add这个任务每隔10秒跑一次
Beat和Worker一起启动
celery -B -A projb worker -l info
运行后可以看到每10秒都会运行一次tasks.add
任务绑定、记录日志、重试
任务绑定、记录日志和重试是Celery中常用的三个高级属性,修改proj/tasks.py,添加div函数
当使用bind=True后,函数的参数发生变化,多出了参数self,相当于把div变成了一个已绑定的方法,通过self可以获得任务的上下文
异常ZeroDivisionError中 as e,e为异常的实例,出现异常后就抛出重试retry
!r:表示为字符串格式化方法,只能用于format,在%中使用会报错
|
|
先启动worker进程
celery -A proj worker -l info
另开一个终端,进入ipython
|
|
可以看到worker端出现一下执行信息:
|
|
换成造成异常的参数
|
|
worker端
|
|
每5条就执行一次,执行完三次以后抛出异常结束

